Chapter 12 - Concatenation and Merging of DataFrames¶
Concatenation of two datasets is vertical¶
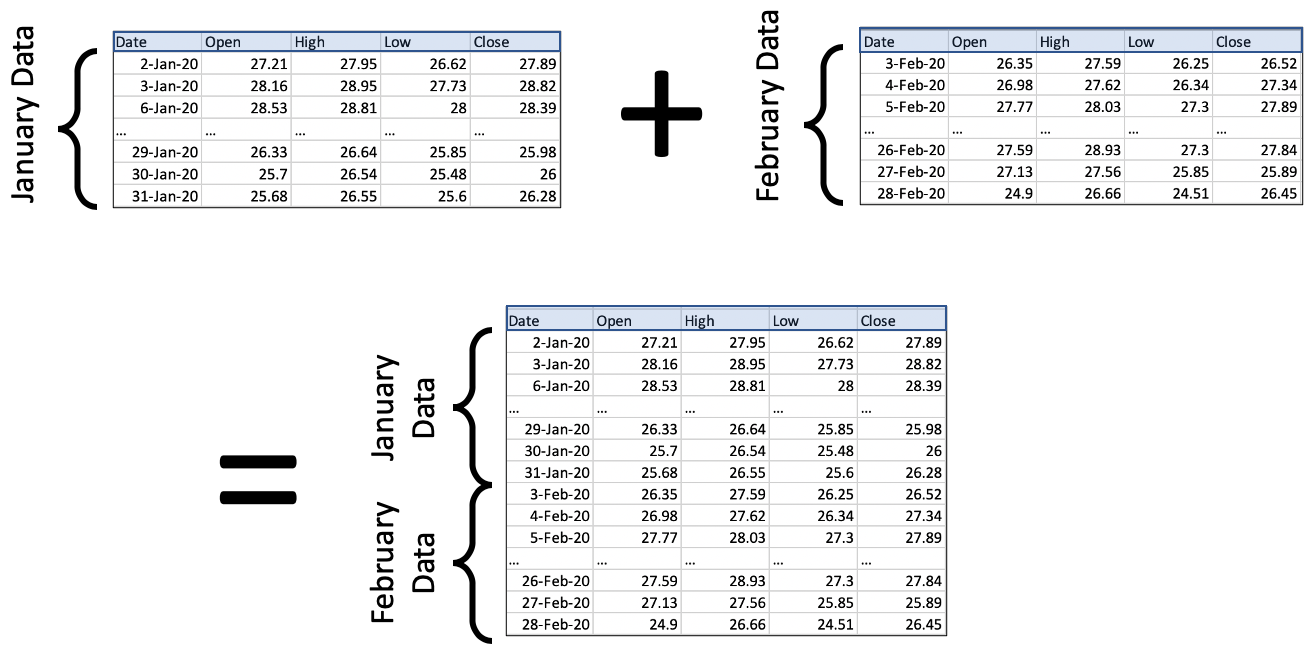
Code for concatenation¶
df_jan = pd.read_csv( '_static/regi-prices-jan-2020.csv' )
df_feb = pd.read_csv( '_static/regi-prices-feb-2020.csv' )
df_2mo = pd.concat( [ df_jan, df_feb ], ignore_index=True )
df_2mo.head()
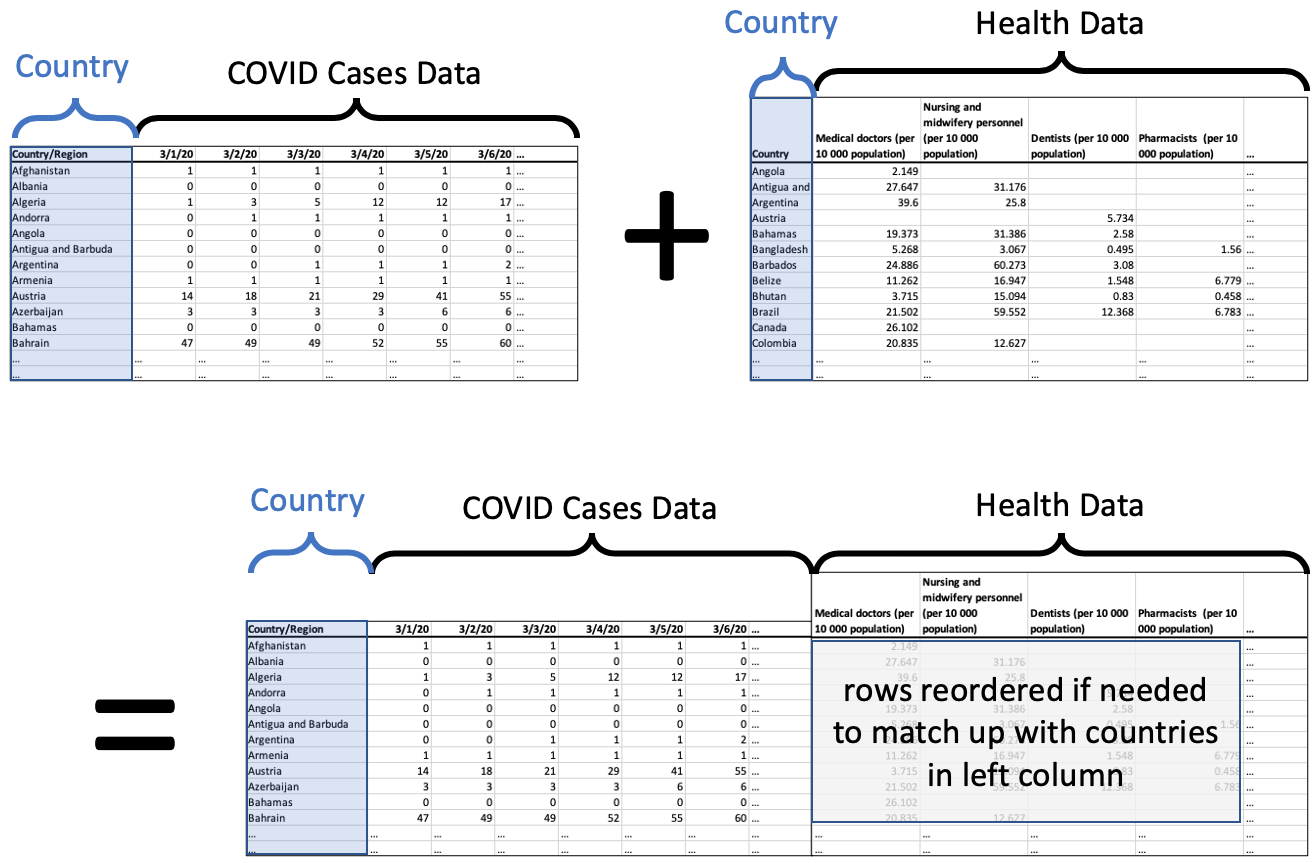
Code for a simple merge¶
df_merged = pd.merge( df_cases, df_health,
left_on='Country/Region', right_on='Country' )
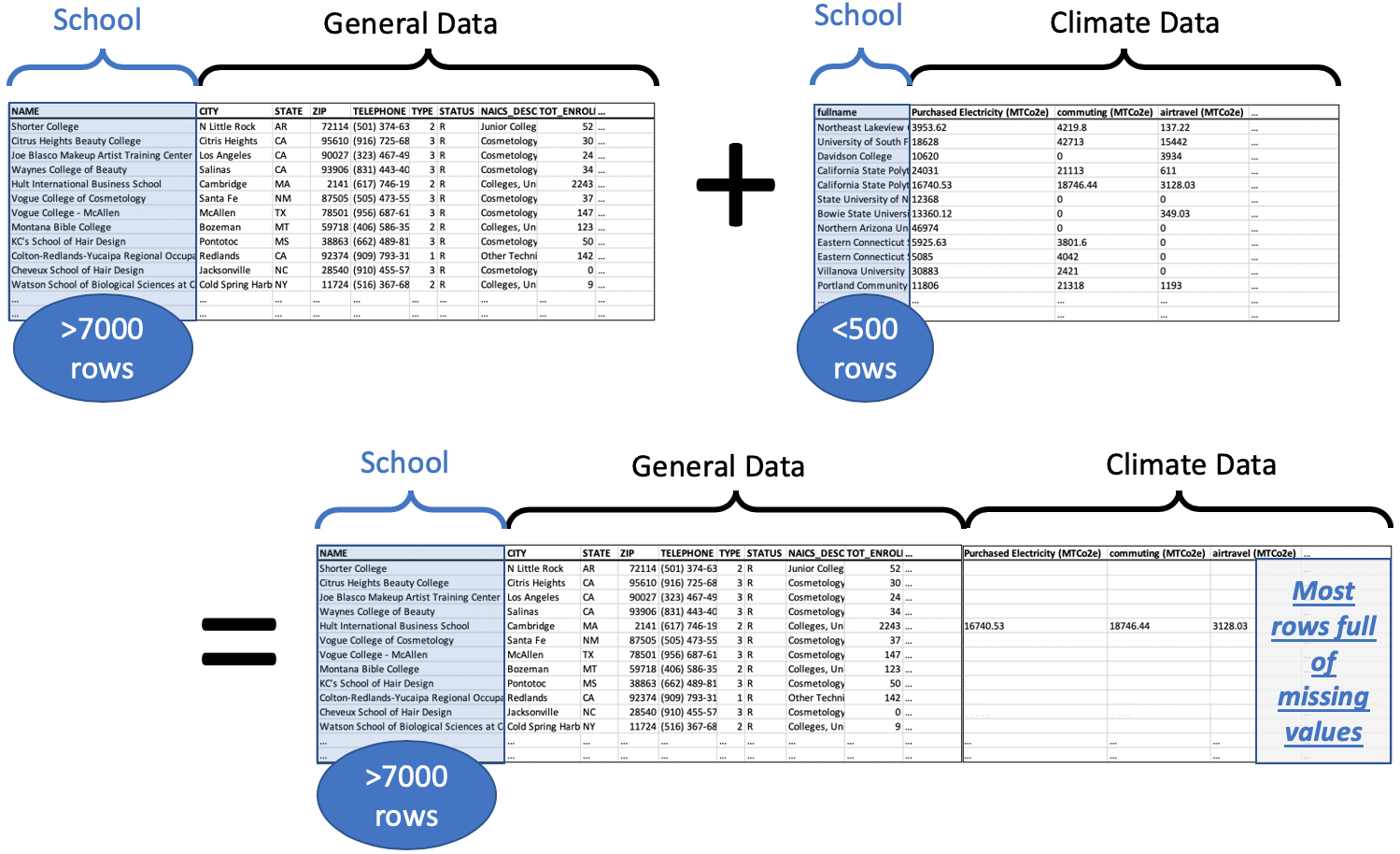
Code for a left join (merge)¶
df_merged = pd.merge( df_big, df_climate,
left_on='NAME', right_on='fullname', how='left' )
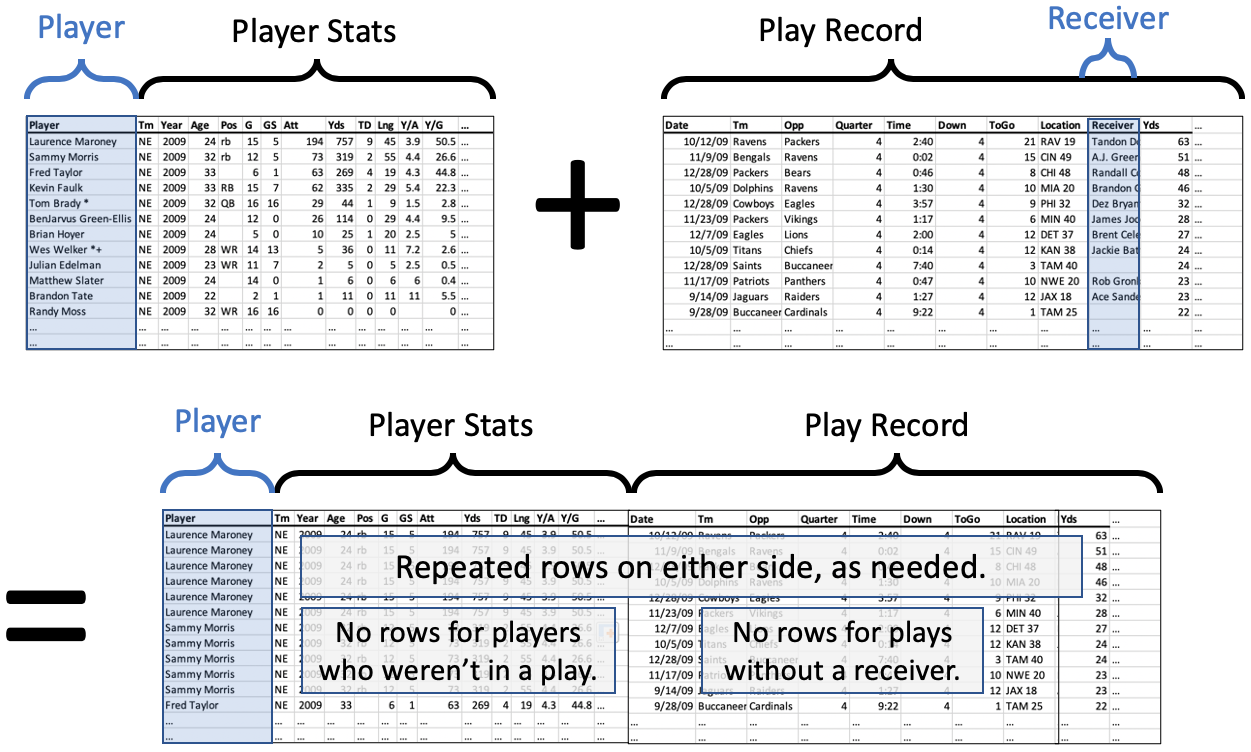
Code for an inner join (merge)¶
An inner join is the default, so you can omit how='inner' in this case.
df_merged = pd.merge( df_players, df_plays,
left_on='NAME', right_on='fullname', how='inner' )
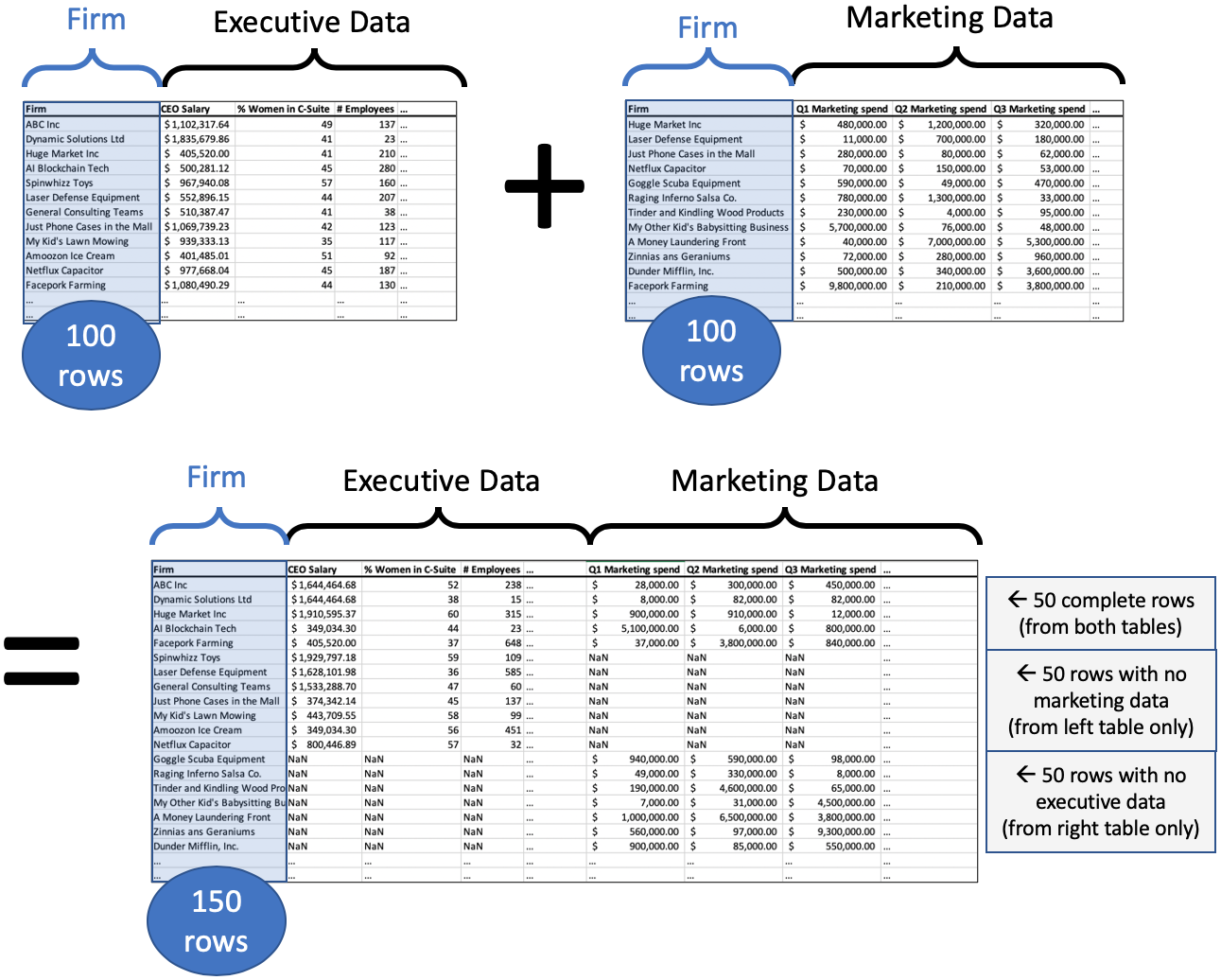
Code for an outer join (merge)¶
df_merged = pd.merge( df_execs, df_marketing,
left_on='NAME', right_on='fullname', how='outer' )
For discussion¶
We will look at four hypothetical situations for merging DataFrames. In each case, you will answer:
- Should we apply
pd.concat()orpd.merge()? - If the answer to 1. is to apply
pd.merge(), then:- How should we merge (inner/left/right/outer)?
- On what column(s) should we merge?
- Do we need to manipulate any column(s) first?
Concat/Merge Example 1¶
(Thanks to Steven Skiena in The Data Science Design Manual for this example, a real project he did with a graduate student.)
Dataset 1: A large sample of news stories about various publicly traded companies from 2015 to 2020, with story release dates and measurements of the sentiments expressed in those news stories
Dataset 2: Records of the the share prices of the publicly traded companies for the same time period
Concat/Merge Example 2¶
Dataset 1: Records of all NCAA Division I hockey games for the 2018 season
Dataset 2: Records of all NCAA Division III hockey games for the 2018 season
For example, the record of a game might contain the home and away team names and scores, number of shots on goal and penalties, MVP name, and attendance number.
Concat/Merge Example 3¶
Dataset 1: Daily weather summaries for the counties in the state of Tennessee in summer 1995
Dataset 2: Hourly electrical prices for each county in the state of Tennessee in summer 1995
Concat/Merge Example 4¶
Dataset 1: The baseline health information gathered from each subject in a drug's clinical trial before the trial begins, together with the information about whether that subject has been randomly assigned the treatment or the placebo
Dataset 2: The responses measured for each subject during and after the trial with respect to the specific problems the drug is trying to address
In-class Exercise 1 (short)¶
In a previous class, we took two datasets and did a simple merge that involved only one column.
- Dataset 1 was the sample of home mortgages from 2018.
- Dataset 2 was created by you, extracting 2016 voting data from this web page.
We extracted the percentage of each state who voted for Trump and added that data as a new column in the home mortgage dataset. We used dict(zip(...)) to convert the voting data into a dictionary and df['column'].map() to apply it to the mortgage dataset.
Redo the same exercise now, but using pd.merge() instead of the tools we used last time. (Last time, you also had to do some plotting and hypothesis testing. There is no need to repeat that. Just update the merging code.)
In-class Exercise 2 (long)¶
In a previous class, we examined a dataset of baseball player salaries.
- Dataset 1 will be a simplified version of that baseball salary dataset, available here.
- Dataset 2 will be the statistics for all batters in Major League Baseball from 1988 through 2016, available here.
Merge the two datasets on player name, team, and year. This will require some of the advanced techniques introduced at the end of the course notes on merging.
NOTE: This will be complex and annoying. We may not complete it before the end of class. Make as much progress as you can, while doing logical/sensible work each step of the way.