Chapter 6 - Single-Table Verbs¶
Data in "tall" form¶
| First | Last | Day | Sales |
|---|---|---|---|
| Amy | Smith | Monday | 39 |
| Amy | Smith | Tuesday | 68 |
| Amy | Smith | Wednesday | 10 |
| Bob | Jones | Monday | 93 |
| Bob | Jones | Tuesday | 85 |
| Bob | Jones | Wednesday | 0 |
From the reading, what is the value of this form of data?
And what is the other name for this form of data?
Data in "wide" form¶
| First | Last | Monday | Tuesday | Wednesday |
|---|---|---|---|---|
| Amy | Smith | 39 | 68 | 10 |
| Bob | Jones | 93 | 85 | 0 |
From the reading, what is the value of this form of data?
And what are the verbs used to convert from tall to wide form, or wide to tall form?
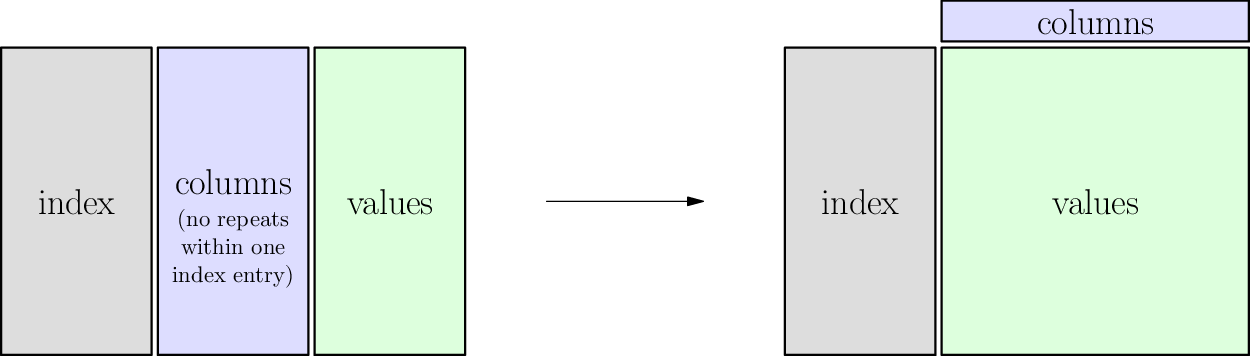
Pivot details¶
Names
- Gray cells are called
index - Blue cells are called
columns - Green cells are called
values
Requirements
- The relationship from
indexandcolumnstovaluesmust be a function.
Guarantees
- That one function will become many functions, each in its own column, one for each value in the original
columnscolumn.
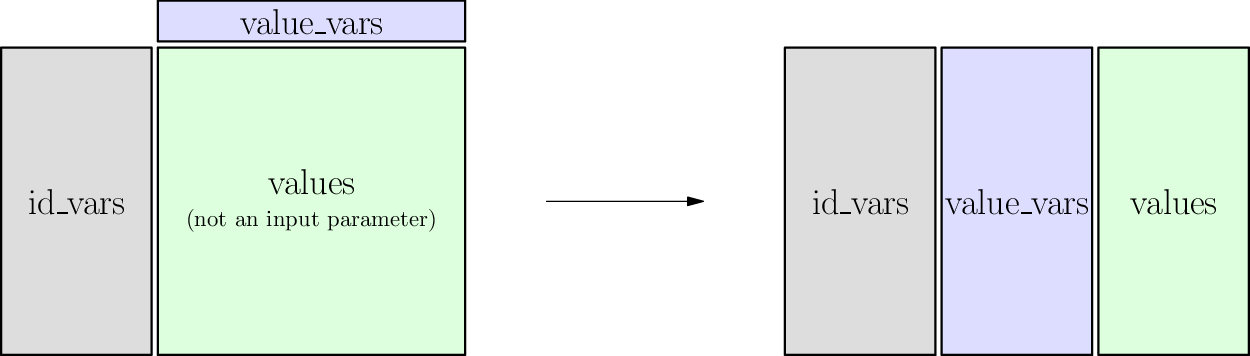
Melt details¶
Names
- Gray columns are called
id_vars - Red column headers are called
value_vars
Requirements
- The
id_varsuniquely identify each row. - The relationship from
id_varsto eachvalue_varscolumn is a function.
Guarantees
- The
value_varscolumn headers will be merged into one single column entitledvariable. - The
value_varscolumn entries will be merged into one single column entitledvalue. - The
id_varsentries will be replicated so that the result is still a function fromid_varsandvariabletovalue.
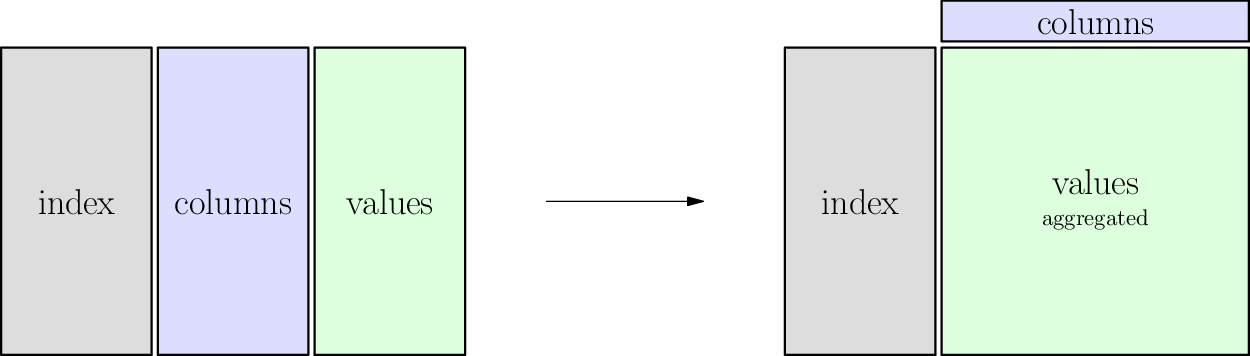
Pivot table details¶
Same as pivot, except:
- The relationship between
indexandcolumnsneed not be a function. - Therefore some values will need to be combined.
- And so we must provide a function that will combine them, called
aggfunc.
Pivot tables are extremely common for summarizing data, especially since there are so many different aggregation functions. Here is a list of all the built-in ones, and you can also code your own.
Exercises¶
After the break in class today, you'll be diving into working on some datasets for practice.
To prepare for that, let's do a few exercises for discussion, to refresh your memory on other pandas tools, functions, and syntax.
Exercise 1¶
Which of the following sentences correctly describes the uses of the pandas functions loc and iloc?
- For a DataFrame
df, you can usedf.loc[...]to look up rows, columns, or cells by their names, anddf.iloc[...]to look up rows, columns, or cells by their zero-based numerical index. - For a DataFrame
df, you can usedf.loc[...]to access rows anddf.iloc[...]to access columns. - For a DataFrame
df, you can usedf.loc[...]to look up one or more rows by integer index anddf.iloc[...]to do the same, but counting from the end of the DataFrame (iloc= "inverted loc"). - For a DataFrame
df, you can usedf[...],df.loc[...], anddf.iloc[...]interchangeably to get access to individual entries in the DataFrame.
Exercise 2¶
If you have a DataFrame in the variable df, which of the following are situations in which you would want to execute the code df["sales"] = 0?
- You want to remove from your DataFrame a column entitled "sales"
- You want to replace the data in an existing "sales" row with zero entries
- You want to add a new row entitled "sales," initially populated with zero entries
- You want to remove from your DataFrame a row entitled "sales"
- You want to replace the data in an existing "sales" column with zero entries
- You want to add a new column entitled "sales," initially populated with zero entries
- You want to replace one existing entry, named "sales," with a zero
- You want to add one new entry, named "sales," initially containing a zero
- You want to remove from your DataFrame one entry, the one named "sales"
Exercise 3¶
Assume we have a DataFrame df with several columns, including "Salary" and "Job Title". How would we find the salaries of anyone whose job title is "Engineer"? (Fill in the blanks.)
indices = df[___________] == __________
salaries = df.loc[____________________]
Exercise 4¶
What happens when we run the code df["column"].apply( f )?
- Python replaces each entry
xindf["column"]with the result off(x) - Python computes and returns the result of
f(df["column"]) - Python computes and returns a new Series containing
f(x)for each entryxindf["columns"] - Python replaces the column
df["column"]with the result off(df["column"])
Exercise 5¶
Assume that we have read a DataFrame df from a CSV file, and provided no default index, so that its index is the integers from 0 to 9.
Assume further that the rows in df each represent data collected in one particular year. The data were collected beginning with the year 1970, and repeating the data collection every five years, so that the first row is from 1970, the second row is from 1975, and so on.
We want the index of df to represent the year of data collection, which is not currently stored in any of the columns of the DataFrame. Which of the following pieces of code would accomplish that goal?
# Option 1:
df.index = df.index*5 + 1965
df.index.name = 'Year'
# Option 2:
df.index = df.index*5 + 1970
df.index.name = 'Year'
# Option 3:
df.index = range(0,50,5) + 1965
df.index.name = 'Year'
# Option 4:
df.index = range(0,50,5) + 1970
df.index.name = 'Year'